Faster web scraping with Python and asyncio
Do you use Jupyter? Are you still sending sequential web requests like a noob? Then this article is for you!
This article is for intermediate Python programmers, so I’m going to skip over a lot of the detail.
I couldn’t have done this without these two books:
Python Concurrency with asyncio by Matthew Fowler
Using Asyncio in Python: Understanding Python’s Asynchronous Programming Features by Caleb Hattingh
These books are great. Buy them!
Packages used in this post
# standard library packages
import asyncio
import gzip
import functools
from functools import partial
from time import perf_counter
import random
# other packages
import requests
import aiohttp
Getting some data to work with
We’ll be using a sample file from the Wikimedia dumps:
WIKIMEDIA_DUMP_URL = "https://dumps.wikimedia.org/enwiki/latest/enwiki-latest-all-titles.gz"
response = requests.get(WIKIMEDIA_DUMP_URL)
The file is a gzip file, so we need to decompress it. gzip.decompress returns a byte string that can be decoded to UTF-8:
titles = gzip.decompress(response.content).decode("utf-8")
Let’s take a look at our data. There are some interesting article titles here. I’m leaving them in for science! No need to hide them.
titles[:100]
'page_namespace\tpage_title\n0\t!\n0\t!!\n0\t!!!\n0\t!!!!!!!\n0\t!!!Fuck_You!!!\n0\t!!!Fuck_You!!!_And_Then_Some\n0'
We make some observations:
- We’ve got one huge string
- There’s a header row, indicating there are two columns:
page_namespaceandpage_title - The file is tab-delimited, indicated by the
\tcharacters - There are new line characters, indicated by the
\ncharacters
I don’t want to process this whole string for this demonstration. Let’s take the first 100k article titles:
num_new_lines = 0
for i in range(len(titles)):
if titles[i] == "\n":
num_new_lines += 1
# we add 1 to the number of lines to account for the header row
if num_new_lines >= 100_000 + 1:
target_index = i
break
This is the position of the new line character immediately after the 100,000th article title:
print(target_index)
2302543
titles_substr = titles[:target_index]
Next, we extract the article titles. We’ll do these things:
- Split the string on new line characters
- Split each line by the tab delimiter and take the second element, which is the article title
- Remove the first element to discard the header row
titles_sample = [line.split('\t')[1] for line in titles_substr.split('\n')]
titles_sample = titles_sample[1:]
The result is a list of 100k article titles:
titles_sample[:10]
['!',
'!!',
'!!!',
'!!!!!!!',
'!!!Fuck_You!!!',
'!!!Fuck_You!!!_And_Then_Some',
'!!!Fuck_You!!!_and_Then_Some',
'!!!_(!!!_album)',
'!!!_(American_band)',
'!!!_(Chk_Chk_Chk)']
print(f"number of article titles: {len(titles_sample):,}")
number of article titles: 100,000
Noice!
Making the requests
We’ll be making the request to URLs looking like this:
WIKIPEDIA_BASE_URL = "https://en.wikipedia.org/wiki/{TITLE}"
Here’s the first URL:
title = titles_sample[0]
url = WIKIPEDIA_BASE_URL.format(TITLE=title)
print(url)
https://en.wikipedia.org/wiki/!
Let’s make a single request:
response = requests.get(url)
The response is a byte string, so we’ll decode it to UTF-8:
response.content.decode('utf-8')[:1000]
'<!DOCTYPE html>\n<html class="client-nojs vector-feature-language-in-header-enabled vector-feature-language-in-main-page-header-disabled vector-feature-language-alert-in-sidebar-enabled vector-feature-sticky-header-disabled vector-feature-page-tools-disabled vector-feature-page-tools-pinned-disabled vector-feature-main-menu-pinned-disabled vector-feature-limited-width-enabled vector-feature-limited-width-content-enabled" lang="en" dir="ltr">\n<head>\n<meta charset="UTF-8"/>\n<title>Exclamation mark - Wikipedia</title>\n<script>document.documentElement.className="client-js vector-feature-language-in-header-enabled vector-feature-language-in-main-page-header-disabled vector-feature-language-alert-in-sidebar-enabled vector-feature-sticky-header-disabled vector-feature-page-tools-disabled vector-feature-page-tools-pinned-disabled vector-feature-main-menu-pinned-disabled vector-feature-limited-width-enabled vector-feature-limited-width-content-enabled";(function(){var cookie=document.cookie.matc'
Note the <title>Exclamation mark - Wikipedia</title>. We have an article about the exclamation mark!
Let’s make a list of URLs we’ll be using for the rest of this post:
urls = [WIKIPEDIA_BASE_URL.format(TITLE=title) for title in titles_sample]
urls[:10]
['https://en.wikipedia.org/wiki/!',
'https://en.wikipedia.org/wiki/!!',
'https://en.wikipedia.org/wiki/!!!',
'https://en.wikipedia.org/wiki/!!!!!!!',
'https://en.wikipedia.org/wiki/!!!Fuck_You!!!',
'https://en.wikipedia.org/wiki/!!!Fuck_You!!!_And_Then_Some',
'https://en.wikipedia.org/wiki/!!!Fuck_You!!!_and_Then_Some',
'https://en.wikipedia.org/wiki/!!!_(!!!_album)',
'https://en.wikipedia.org/wiki/!!!_(American_band)',
'https://en.wikipedia.org/wiki/!!!_(Chk_Chk_Chk)']
The sequential way
Let’s first make 10 requests sequentially using the requests package. This is painfully slow:
def sequential_requests(urls):
for url in urls:
response = requests.get(url)
We’ll time how long it takes on average by running it 5 times:
%%timeit -n 1 -r 5
sequential_requests(urls[:10])
4.43 s ± 76.7 ms per loop (mean ± std. dev. of 5 runs, 1 loop each)
Boo-urns!
The async way
We’ll be using asyncio and aiohttp to make async requests.
Creating a timing decorator
I can’t use cell magic here so will create an async timer decorator to use in the rest of this post:
def async_timer(num_iter):
def timer_decorator(func):
@functools.wraps(func)
async def wrapper(*args, **kwargs):
results = []
for i in range(num_iter):
print(f"running iteration {i + 1}")
start_time = perf_counter()
await func(*args, **kwargs)
end_time = perf_counter()
time_taken = end_time - start_time
print(f"iteration {i + 1} took {time_taken:.2f} seconds")
results.append(time_taken)
mean_time = sum(results) / len(results)
print(f"Average time over {num_iter} iterations: {mean_time:.2f} seconds")
return wrapper
return timer_decorator
Write some coroutines
What’s a coroutine? I can’t describe them better than Matthew Fowler, so here’s a quote from his book from page 24:
Think of a coroutine like a regular Python function but with the superpower that it can pause its execution when it encounters an operation that could take a while to complete. When that long-running operation is complete, we can “wake up” our paused coroutine and finish executing any other code in that coroutine. While a paused coroutine is waiting for the operation it paused for to finish, we can run other code. This running of other code while waiting is what gives our application concur- rency. We can also run several time-consuming operations concurrently, which can give our applications big performance improvements.
We create coroutines using the async keyword. We tell them to pause using the await keyword.
Coroutines aren’t scheduled for execution until we schedule them for execution! To do this, we wrap our coroutines in Tasks, which we’ll create using asyncio.create_task.
Here’s how we’ll be creating our list of tasks to complete:
- We create a single task by passing our coroutine
make_requestintoasyncio.create_task. - We do this for each url in our urls list
We then wait for our tasks to complete using asyncio.gather:
- We specify
return_exceptions=Truebecause the default behaviour ofasyncio.gatheris to raise the first exception it encounters. - This leaves any remaining tasks running in the background even though it looks like code execution has stopped.
- We instead want
asyncio.gatherto return exceptions in its list of results. This allows us to handle any exceptions as we see fit.
async def make_request(session, url):
async with session.get(url) as response:
return await response.text()
@async_timer(num_iter=5)
async def make_requests(urls):
async with aiohttp.ClientSession() as session:
tasks = [asyncio.create_task(make_request(session, url)) for url in urls]
return await asyncio.gather(*tasks, return_exceptions=True)
We’ll be running make_requests 5 times just like we did for our sequential requests using the @async_timer(num_iter=5) decorator:
results = await make_requests(urls[:10])
running iteration 1
iteration 1 took 0.64 seconds
running iteration 2
iteration 2 took 0.61 seconds
running iteration 3
iteration 3 took 0.64 seconds
running iteration 4
iteration 4 took 0.61 seconds
running iteration 5
iteration 5 took 1.55 seconds
Average time over 5 iterations: 0.81 seconds
That’s a lot better, but not much better. We see the benefit of the async approach when we make a larger number of requests:
await make_requests(urls[:1_000])
running iteration 1
iteration 1 took 16.05 seconds
running iteration 2
iteration 2 took 32.65 seconds
running iteration 3
iteration 3 took 65.37 seconds
running iteration 4
iteration 4 took 65.73 seconds
running iteration 5
iteration 5 took 32.74 seconds
Average time over 5 iterations: 42.51 seconds
That’s a lot faster! We’re making about 60 requests per second.
Why is this so much faster?
We can see that aiohttp opens up a whole lotta non-blocking sockets!
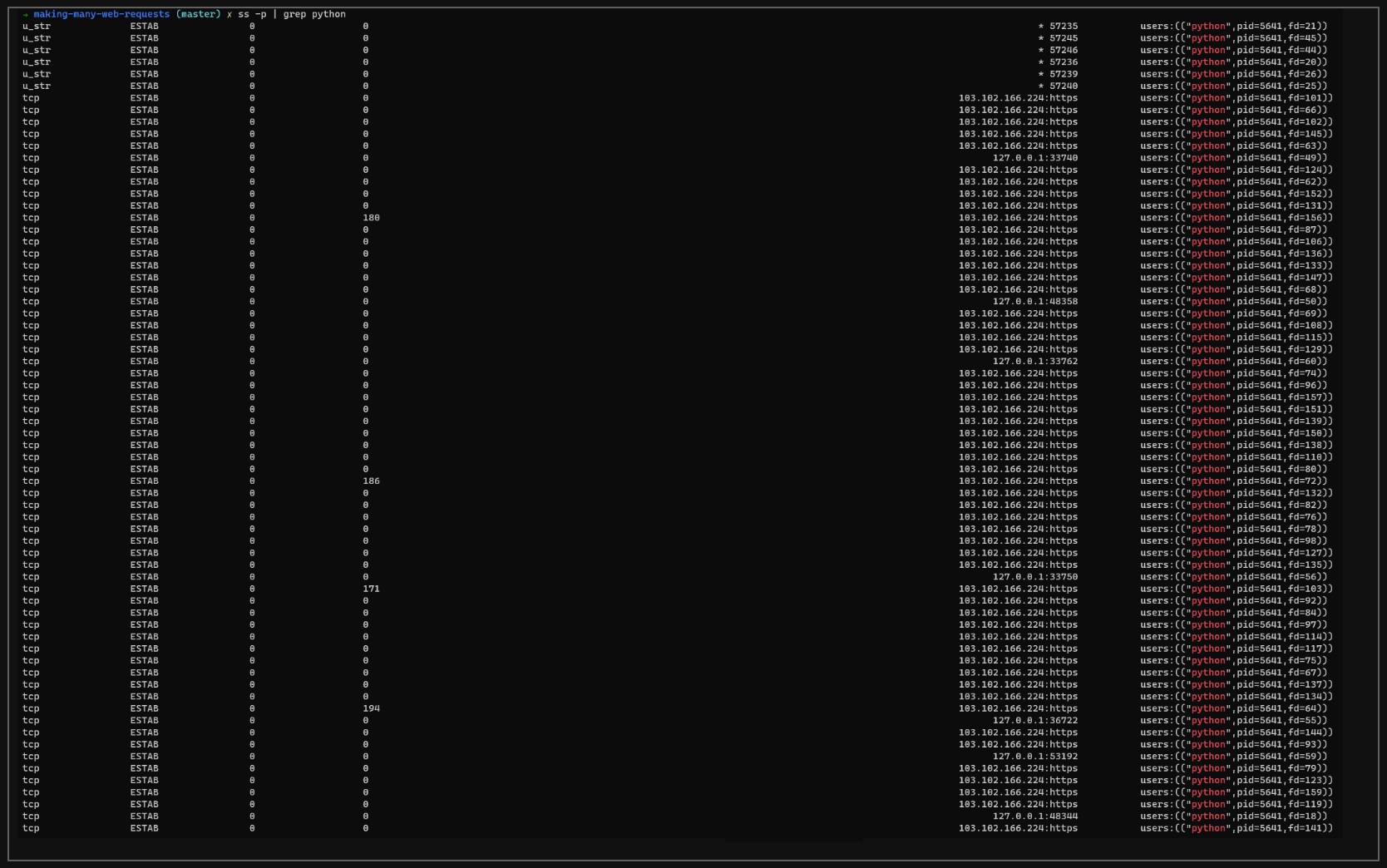
What’s happening under the hood? In the aiohttp documentation, they give us an insight, comparing it to the requests package. Firstly, they describe what happens in the requests package when we call .get():
When doing
response.textinrequests, you just read an attribute. The call to.get()already preloaded and decoded the entire response payload, in a blocking manner.
Then on how aiohttp does it:
aiohttploads only the headers when.get()is executed, letting you decide to pay the cost of loading the body afterward, in a second asynchronous operation. Hence theawait response.text().
What if we want to handle exceptions?
Cancelling pending tasks on the first exception
What if we want to shut down any remaining tasks on an exception? We can use asyncio.wait for more granular control.In the below, we do these things:
- We simulate a GET request timing out in
make_request. We set the timeout to be some random integer. - We create a list of tasks to execute using
asyncio.create_task. Each task created using this function is immediately scheduled for execution. - We issue
asyncio.wait(tasks, return_when=asyncio.FIRST_EXCEPTION). On the first exception (in this case, aaiohttp.ClientTimeouterror), we return twosets:- The
done setcontains tasks that are either completed successfully or completed with an exception. - The
pending setcontains tasks which we don’t have results for yet.
- The
- We loop through the
done setto demonstrate that at least one task has returned an exception. - We then loop through all tasks in the
pending setand cancel them.- If we don’t cancel them like this, the tasks continue to run despite our exception.
- We wait for a few seconds and demonstrate that all pending tasks have been cancelled.
async def make_request(session, url):
# set a random request timeout to demonstrate cancelling pending
# tasks on a TimeoutError
timeout = aiohttp.ClientTimeout(total=random.random() * 10)
async with session.get(url, timeout=timeout) as response:
return await response.text()
async def make_requests(urls):
async with aiohttp.ClientSession() as session:
tasks = [asyncio.create_task(make_request(session, url))
for url in urls]
done, pending = await asyncio.wait(tasks, return_when=asyncio.FIRST_EXCEPTION)
print(f'number of done tasks: {len(done)}')
msg_prefix = "task result: "
for task in done:
try:
result = task.result()
print(msg_prefix + 'task completed successfully!')
except asyncio.TimeoutError:
print(msg_prefix + "task timed out!")
print(f'number of pending tasks to cancel: {len(pending)}')
for pending_task in pending:
pending_task.cancel()
# wait a few seconds to demonstrate if our pending tasks were actually cancelled
await asyncio.sleep(2)
for i, pending_task in enumerate(pending):
print(f'pending task {i + 1} cancelled? {pending_task.cancelled()}')
await make_requests(urls[:30])
number of done tasks: 1
task result: task timed out!
number of pending tasks to cancel: 29
pending task 1 cancelled? True
pending task 2 cancelled? True
pending task 3 cancelled? True
pending task 4 cancelled? True
pending task 5 cancelled? True
pending task 6 cancelled? True
pending task 7 cancelled? True
pending task 8 cancelled? True
pending task 9 cancelled? True
pending task 10 cancelled? True
pending task 11 cancelled? True
pending task 12 cancelled? True
pending task 13 cancelled? True
pending task 14 cancelled? True
pending task 15 cancelled? True
pending task 16 cancelled? True
pending task 17 cancelled? True
pending task 18 cancelled? True
pending task 19 cancelled? True
pending task 20 cancelled? True
pending task 21 cancelled? True
pending task 22 cancelled? True
pending task 23 cancelled? True
pending task 24 cancelled? True
pending task 25 cancelled? True
pending task 26 cancelled? True
pending task 27 cancelled? True
pending task 28 cancelled? True
pending task 29 cancelled? True
Nice!
What if I have a huge number of tasks and want to avoid creating them up-front?
An issue with creating an iterable of Tasks is that we need to spend some time to create it before we can begin executing them:
async def dummy_task():
pass
async def make_requests(num_tasks):
start_time = perf_counter()
tasks = [asyncio.create_task(dummy_task()) for _ in range(num_tasks)]
end_time = perf_counter()
await asyncio.gather(*tasks)
print(f'took {end_time - start_time:.4f} seconds')
print(f'number of tasks to run: {len(tasks):,}')
for num_tasks in [10**x for x in range(1, 7)]:
await make_requests(num_tasks=num_tasks)
took 0.0001 seconds
number of tasks to run: 10
took 0.0005 seconds
number of tasks to run: 100
took 0.0073 seconds
number of tasks to run: 1,000
took 0.0683 seconds
number of tasks to run: 10,000
took 0.4629 seconds
number of tasks to run: 100,000
took 7.3401 seconds
number of tasks to run: 1,000,000
How can we avoid creating tasks up front? We can use generators with async workers and asyncio.Queues!
In the below, we do these things:
- We create a queue using
asyncio.Queue. I’ll explain theQUEUE_SIZEin a bit. - We have an async producer function named
producer_fn.- Its responsibility is to put tasks onto the queue.
- We have an async worker function named
worker_fn.- Its responsibility is to get tasks from the queue and complete to them.
- We initialise an asyncio.Queue with a max queue size of
5. Setting a maximum queue size is the key to solving this problem. - Now on the
QUEUE_SIZE:- If we had an unbounded queue, the
producer_fnwould quickly create all tasks we want to execute, giving us a result like the one we saw before. - When our queue reaches
QUEUE_SIZE, the call toawait queue.put()blocks until a worker removes an item from the queue.
- If we had an unbounded queue, the
- Our workers are run in an infinite loop. To exit the infinite loop while cleaning up after ourselves, we do these things:
- When we interrupt the kernel, an
asyncio.CancelledErroris raised. We catch it in ourrun_taskscoroutine. - We cancel the running workers and print their statuses to confirm that our cancellations have worked.
- When we interrupt the kernel, an
QUEUE_SIZE = 5
NUM_WORKERS = 10
async def make_request(session, url):
async with session.get(url) as response:
return await response.text()
async def producer_fn(queue, urls):
for url in urls:
if queue.qsize() == QUEUE_SIZE:
print('PRODUCER - QUEUE FULL...waiting...')
await queue.put(url)
print(f'producer enqueued {url}')
print('producer exhausted')
async def worker_fn(queue, session):
task = asyncio.current_task()
while True:
val = await queue.get()
print(f"--- worker {task.get_name()} got {val} from queue")
result = await make_request(session, url)
print(f"--- worker {task.get_name()} completed task")
queue.task_done()
async def run_tasks(urls):
queue = asyncio.Queue(QUEUE_SIZE)
async with aiohttp.ClientSession() as session:
producer = asyncio.create_task(producer_fn(queue, urls))
workers = [asyncio.create_task(worker_fn(queue, session), name=f'worker_{i}') for i in range(NUM_WORKERS)]
try:
await asyncio.gather(producer, *workers)
except asyncio.CancelledError:
print('received CancelledError...killing workers')
[w.cancel() for w in workers]
for w in workers:
print(f'worker cancelled? {w.cancelled()}')
await run_tasks(urls[:20])
producer enqueued https://en.wikipedia.org/wiki/!
producer enqueued https://en.wikipedia.org/wiki/!!
producer enqueued https://en.wikipedia.org/wiki/!!!
producer enqueued https://en.wikipedia.org/wiki/!!!!!!!
producer enqueued https://en.wikipedia.org/wiki/!!!Fuck_You!!!
PRODUCER - QUEUE FULL...waiting...
--- worker worker_0 got https://en.wikipedia.org/wiki/! from queue
--- worker worker_1 got https://en.wikipedia.org/wiki/!! from queue
--- worker worker_2 got https://en.wikipedia.org/wiki/!!! from queue
--- worker worker_3 got https://en.wikipedia.org/wiki/!!!!!!! from queue
--- worker worker_4 got https://en.wikipedia.org/wiki/!!!Fuck_You!!! from queue
producer enqueued https://en.wikipedia.org/wiki/!!!Fuck_You!!!_And_Then_Some
producer enqueued https://en.wikipedia.org/wiki/!!!Fuck_You!!!_and_Then_Some
producer enqueued https://en.wikipedia.org/wiki/!!!_(!!!_album)
producer enqueued https://en.wikipedia.org/wiki/!!!_(American_band)
producer enqueued https://en.wikipedia.org/wiki/!!!_(Chk_Chk_Chk)
PRODUCER - QUEUE FULL...waiting...
--- worker worker_5 got https://en.wikipedia.org/wiki/!!!Fuck_You!!!_And_Then_Some from queue
--- worker worker_6 got https://en.wikipedia.org/wiki/!!!Fuck_You!!!_and_Then_Some from queue
--- worker worker_7 got https://en.wikipedia.org/wiki/!!!_(!!!_album) from queue
--- worker worker_8 got https://en.wikipedia.org/wiki/!!!_(American_band) from queue
--- worker worker_9 got https://en.wikipedia.org/wiki/!!!_(Chk_Chk_Chk) from queue
producer enqueued https://en.wikipedia.org/wiki/!!!_(album)
producer enqueued https://en.wikipedia.org/wiki/!!!_(band)
producer enqueued https://en.wikipedia.org/wiki/!!!_(disambiguation)
producer enqueued https://en.wikipedia.org/wiki/!!!_discography
producer enqueued https://en.wikipedia.org/wiki/!!Destroy-Oh-Boy!!
PRODUCER - QUEUE FULL...waiting...
--- worker worker_0 completed task
--- worker worker_0 got https://en.wikipedia.org/wiki/!!!_(album) from queue
producer enqueued https://en.wikipedia.org/wiki/!!Fuck_you!!
PRODUCER - QUEUE FULL...waiting...
--- worker worker_1 completed task
--- worker worker_1 got https://en.wikipedia.org/wiki/!!!_(band) from queue
producer enqueued https://en.wikipedia.org/wiki/!!Going_Places!!
PRODUCER - QUEUE FULL...waiting...
--- worker worker_2 completed task
--- worker worker_2 got https://en.wikipedia.org/wiki/!!!_(disambiguation) from queue
producer enqueued https://en.wikipedia.org/wiki/!!Que_Corra_La_Voz!!
PRODUCER - QUEUE FULL...waiting...
--- worker worker_3 completed task
--- worker worker_3 got https://en.wikipedia.org/wiki/!!!_discography from queue
producer enqueued https://en.wikipedia.org/wiki/!!_(chess)
PRODUCER - QUEUE FULL...waiting...
--- worker worker_4 completed task
--- worker worker_4 got https://en.wikipedia.org/wiki/!!Destroy-Oh-Boy!! from queue
--- worker worker_5 completed task
--- worker worker_5 got https://en.wikipedia.org/wiki/!!Fuck_you!! from queue
producer enqueued https://en.wikipedia.org/wiki/!!_(disambiguation)
producer exhausted
--- worker worker_8 completed task
--- worker worker_8 got https://en.wikipedia.org/wiki/!!Going_Places!! from queue
--- worker worker_9 completed task
--- worker worker_9 got https://en.wikipedia.org/wiki/!!Que_Corra_La_Voz!! from queue
--- worker worker_6 completed task
--- worker worker_6 got https://en.wikipedia.org/wiki/!!_(chess) from queue
--- worker worker_0 completed task
--- worker worker_0 got https://en.wikipedia.org/wiki/!!_(disambiguation) from queue
--- worker worker_1 completed task
--- worker worker_3 completed task
--- worker worker_2 completed task
--- worker worker_4 completed task
--- worker worker_5 completed task
--- worker worker_8 completed task
--- worker worker_9 completed task
--- worker worker_6 completed task
--- worker worker_0 completed task
--- worker worker_7 completed task
received CancelledError...killing workers
worker cancelled? True
worker cancelled? True
worker cancelled? True
worker cancelled? True
worker cancelled? True
worker cancelled? True
worker cancelled? True
worker cancelled? True
worker cancelled? True
worker cancelled? True
What if I want to retry failed requests?
This is an idea from p258 of Matthew Fowler’s great book Python Concurrency with asyncio:
- We create a
retrycoroutine, which wraps the coroutine we want to retry (make_request) - We specify some arguments in our calls to
retry:- The maximum number of times we want to retry (
max_retries) - The number of seconds before we decide that our request has timed out (
timeout) - The number of seconds between our retry attempts (
retry_interval)
- The maximum number of times we want to retry (
- If our
retrycoroutine exceeds themax_retrynumber, we raise aTooManyRetriesexception, which is caught in our entry point coroutine,make_requests - We accumulate our successful requests along with our failed requests for future use
class TooManyRetries(Exception):
def __str__(self):
class_name = type(self).__name__
exception_args = self.args
if len(exception_args) > 0:
return f'{class_name}: {exception_args[0]}'
return class_name
async def retry(coro, url, max_retries=2, timeout=2.0, retry_interval=1.0):
for retry_num in range(max_retries):
try:
return await asyncio.wait_for(coro, timeout=timeout)
except Exception as e:
# catch any exception because we want to retry upon any failure
print(f'request to {url} failed. (tried {retry_num + 1} times)')
await asyncio.sleep(retry_interval)
raise TooManyRetries(url)
async def make_request(session, url):
async with session.get(url) as response:
result = await response.text()
print(f'request to {url} completed successfully!')
return result
async def make_requests(urls, timeout_seconds=2.0):
results = []
failed = []
async with aiohttp.ClientSession() as session:
make_request_func = partial(make_request, session)
# we set the name of the task to recover it during exception handling
pending_tasks = [asyncio.create_task(retry(make_request_func(url),
url,
max_retries=2,
timeout=timeout_seconds,
retry_interval=1.0),
name=url) for url in urls]
# process any tasks that completed successfully or completed with an exception
while pending_tasks:
done, pending_tasks = await asyncio.wait(pending_tasks, return_when=asyncio.FIRST_COMPLETED)
for task in done:
if task.exception() is not None:
task_name = task.get_name()
print(task.exception())
failed.append(str(task.exception()))
else:
results.append(task.result())
return results, failed
Let’s run it with a short timeout duration to inspect our retrying behaviour:
results, failed = await make_requests(urls[:10], timeout_seconds=0.5)
request to https://en.wikipedia.org/wiki/!! completed successfully!
request to https://en.wikipedia.org/wiki/!!!Fuck_You!!! completed successfully!
request to https://en.wikipedia.org/wiki/!!!_(!!!_album) completed successfully!
request to https://en.wikipedia.org/wiki/!!!_(American_band) completed successfully!
request to https://en.wikipedia.org/wiki/!!!_(Chk_Chk_Chk) completed successfully!
request to https://en.wikipedia.org/wiki/!!! completed successfully!
request to https://en.wikipedia.org/wiki/! failed. (tried 1 times)
request to https://en.wikipedia.org/wiki/!!!!!!! failed. (tried 1 times)
request to https://en.wikipedia.org/wiki/!!!Fuck_You!!!_And_Then_Some failed. (tried 1 times)
request to https://en.wikipedia.org/wiki/!!!Fuck_You!!!_and_Then_Some failed. (tried 1 times)
request to https://en.wikipedia.org/wiki/! failed. (tried 2 times)
request to https://en.wikipedia.org/wiki/!!!!!!! failed. (tried 2 times)
request to https://en.wikipedia.org/wiki/!!!Fuck_You!!!_And_Then_Some failed. (tried 2 times)
request to https://en.wikipedia.org/wiki/!!!Fuck_You!!!_and_Then_Some failed. (tried 2 times)
TooManyRetries: https://en.wikipedia.org/wiki/!!!!!!!
TooManyRetries: https://en.wikipedia.org/wiki/!!!Fuck_You!!!_and_Then_Some
TooManyRetries: https://en.wikipedia.org/wiki/!!!Fuck_You!!!_And_Then_Some
TooManyRetries: https://en.wikipedia.org/wiki/!
Nice! How many successful requests do we have?
len(results)
6
Let’s see how many characters each successful result contains:
print([len(result) for result in results])
[41274, 73642, 73078, 115246, 115237, 114936]
How many failed requests do we have?
len(failed)
4
What have they returned?
failed
['TooManyRetries: https://en.wikipedia.org/wiki/!!!!!!!',
'TooManyRetries: https://en.wikipedia.org/wiki/!!!Fuck_You!!!_and_Then_Some',
'TooManyRetries: https://en.wikipedia.org/wiki/!!!Fuck_You!!!_And_Then_Some',
'TooManyRetries: https://en.wikipedia.org/wiki/!']
Good!
Conclusion
While I’m no expert in asynchronous programming, the journey so far has been fulfilling.
I hope that I’ve inspired you to start your own asyncio adventure!
Justin